
In the beginning, we had SQL. Wait, no, scratch that.
In the beginning, we had text files. The earliest web applications (or web pages that did application like things) would read and write information to and from simple text files on the server. Maybe XML, maybe CSV, maybe some strange custom format. It was unixy and good.
That is, it was good until a traffic spike happened and you started having to deal with file locking, race conditions, and the unreliability of physical spinning discs for storing data.
So after the beginning, we had SQL, and relational database management systems (RDMS). It’s not that databases didn’t have their own set of problems, but they were a specialized tool for reading and writing data so we, the programmers, didn’t need to deal with that sort of code. It also helped that SQL was a well established industry standard for storing business related data.
For some developers though, SQL itself became a problem at the application level. Writing the same sort of queries over and over again was tedious, and multiple developers using different SQL styles could create confusion in a code-base — plus what happens when you want to switch from a relational database store to something like redis or memcached, and your application is a bunch of random SQL all over the place.
Software engineers wanted a different way to Create, Read, Update, and Delete their data, and so CRUD models were born.
The code samples in this article were tested against SugarCRM CE 6.5.10, but the concepts should apply to future and past versions of the platform.
SugarCRM’s Data Model
A CRUD model class is one that allow you to completely manage your data without writing a single line of SQL code. Behind the scenes the application is still creating and running SQL, but these details have been abstracted away from the developer.
Before we get to SugarCRM’s models, lets take a look at its basic database handling. While modern version of SugarCRM do provide a model system, the developer culture around the platform hasn’t fully embraced them, so you’ll want to be familiar with running raw SQL queries.
To get a database resource instance and run a query, use the following code.
$db = DBManagerFactory::getInstance();
$industry = $_POST['Industry'];
$result = $db->query('SELECT * FROM accounts
WHERE industry = "' . $db->quote($industry).'"');
while($row = $db->fetchRow($result))
{
var_dump($row['name']);
}
This is a very old PHP pattern for fetching data. Notice that there’s no parameterized queries — WHERE clauses are built by the client developer with string concatenation and user input needs to be escaped manually with the quote method to avoid cross site scripting bugs.
$result = $db->query('SELECT * FROM accounts
WHERE industry = ' . $db->quote($industry));
There’s no parameterized queries because the database resource management class (MysqliManager for MySQL) doesn’t use PDO. SugarCRM is old enough that its objects wrap PHP’s original, non-object-oriented, database functions. If you want to see for yourself, just poke around the manager classes.
#File: include/database/MysqliManager.php
public function getAffectedRowCount($result)
{
return mysqli_affected_rows($this->getDatabase());
}
Like elsewhere in the platform, rather than spend time and resources on refactoring SugarCRM has stuck with these classes to maintain compatibility with existing code in the wild and conserve their own resources for new features.
You’ll see this sort of “just because a new pipe gets invented doesn’t mean you’re going to rip the plumbing out of your house” philosophy all over the SugarCRM codebase. You don’t have to like it, but you do need to accept that it’s how things are done if you want to get things done with the platform.
SugarCRM Beans
Fortunately, for those of use who can see the benefits of a proactive approach, modern versions of SugarCRM do have a model system for performing CRUD operations. However, instead of calling these objects models, SugarCRM calls them Beans.
The term bean has a weird history in computer science circles. Back when Sun Microsystems was looking for a name for its new virtual machine based programming language, it decided to hop on the second wave American coffee fad and call its language Java. Later, while trying to create some standardized coding conventions, the idea of JavaBeans was invented, which wikipedia describes as
JavaBeans are reusable software components for Java. Practically, they are classes written in the Java programming language conforming to a particular convention.
Because coffee beans. Marketing! Excelsior!
Next, the enterprise folks got on board with the concept and created Enterprise JavaBeans because Enterprise! Sales! Excelsior!
Despite the history of the term, the easiest way to think of a SugarCRM bean is as an ActiveRecord model class, and a model class that brings along extra system functionality for free. We’re not going to go too in depth to that extra functionality today, but if you go digging deeper on your own keep this in mind.
While it’s not required that a SugarCRM module define a bean, each module that does define a bean typically defines a single bean. Because of that, beans are known by their module names.
Let’s consider the Accounts module. This module defines an Accounts bean. To instantiate the bean, we use the BeanFactory class
$account = BeanFactory::getBean('Accounts');
var_dump($account);
When you var_dump the $account variable, you’d see a class of Account.
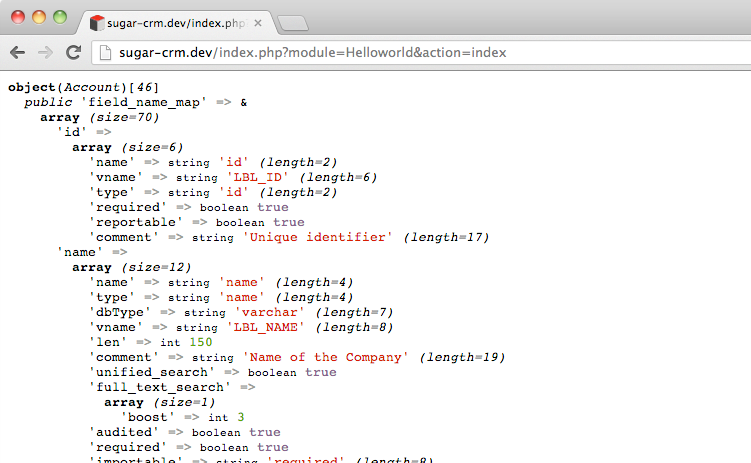
If follow this hierarchy all the way down
#File: modules/Accounts/Account.php
class Account extends Company {
#File: include/SugarObjects/templates/company/Company.php
class Company extends Basic
#File: include/SugarObjects/templates/basic/Basic.php
class Basic extends SugarBean
#File: data/SugarBean.php
class SugarBean
you can see that SugarCRM bean models all inherit from the the base SugarBean class, and most (if not all) do this via the Basic class. These are the classes that provide the shared Object Relational Mapping code (ORM).
An empty bean object isn’t very interesting. Let’s try loading some data. If I was a horrible person I’d try to come up with an un-roasted/roasted coffee bean analogy. Be glad I’m only partly horrible.
We’re going to run this code from the listview action method we created in our Hello World module, but you should be able to run the code anywhere in a bootstrapped SugarCRM environment. Give the following a try
#File: modules/Helloworld/controller.php
public function action_listview()
{
$account = BeanFactory::getBean('Accounts')
->retrieve_by_string_fields(array('name'=>'Q.R.&E. Corp'));
var_dump($account->name);
var_dump($account->industry);
exit(__METHOD__);
}
If you load the hello world module page
http://sugar-crm.dev/index.php?module=Helloworld
you should see something like the following (Assuming you installed SugarCRM with the sample data)
string 'Q.R.&E. Corp' (length=12)
string 'Shipping' (length=8)
Here we’re using the retrieve_by_string_fields method to grab the Account bean object for the single account with the name Q.R.&E. Corp, and then using var_dump to output the name (redundantly), and the industry field. When SugarCRM loads a bean’s data, it populates the object properties directly — there’s no separate $_data array to keep properties system logic properties separate from business logic properties.
However, you can also grab a field value with the getFieldValue method
var_dump( $account->getFieldValue('industry') );
The two techniques are practically identical — the only exception is getFieldValue will do some data normalization if a property doesn’t exist or if its a boolean. You can see that in the SugarBean class.
#File: data/SugarBean.php
function getFieldValue($name)
{
if (!isset($this->$name)){
return FALSE;
}
if($this->$name === TRUE){
return 1;
}
if($this->$name === FALSE){
return 0;
}
return $this->$name;
}
The main benefit of getFieldValue seems to be avoiding PHP Notice: Undefined property: errors when dealing with unknown objects
//generates notice
echo $bean->non_existant_prop;
//silently does nothing
echo $bean->getFieldValue('non_existant_prop');
While SugarCRM beans don’t have a method for fetching all the data properties of an object, they do keep a list of which properties are data/business-logic fields. With that information, it’s relatively easy to gin up some code to get a data array
$data = array();
foreach(array_keys($account->field_defs) as $key)
{
$data[$key] = $account->{$key};
}
var_dump($data);
If you need to update a model’s information, it’s as easy as changing the data property in the object, and then calling its save method.
$account->name = 'Q.R.&E. Corporation';
$account->save();
To make a new object you’d do the same, but start with an empty object.
$account = BeanFactory::getBean('Accounts');
$account->name = 'FooBazBar Corp';
$account->save();
We’ve got the create, read, and update of CRUD handled. That leaves delete. Interestingly, SugarCRM’s bean modes do not have a delete method. Instead, they have a mark_delete method.
$account = BeanFactory::getBean('Accounts')
->retrieve_by_string_fields(array('name'=>'FooBazBar Corp'));
$account->mark_deleted();
$account->save();
Every bean in SugarCRM has a column named deleted that determines if an object is still “in the system” or not. This is an old design pattern that’s fallen out of favor in recent years, but it makes sense for a CRM system. The whole idea of a CRM is you capture all the business activity being performed by your company and run analytics on it. Your sales guy may never want to see FooBazBar Corp again so he deletes it — but your analytics gal may want to know that FooBazBar Corp was a lead at some point. So instead of destroying the data in the database, we just set its deleted column to 1, and the UI generating code knows not to display these records to general users.
As you can see, while the syntax may differ slightly, working with single SugarCRM beans looks a lot like working with single ActiveRecord CRUD models.
SugarCRM Collections
While SugarCRM doesn’t provide collection models, beans do contain a number of methods for fetching arrays of model objects.
First, a note about a method we’ve already seen.
$account = BeanFactory::getBean('Accounts')
->retrieve_by_string_fields(array('billing_address_country'=>'USA'));
var_dump($account->name);
The retrieve_by_string_fields method will search your SugarCRM database and return the first item it finds. So, the above code will only return a single account, even though it’s very likely you’ll have more than one Account bean with a billing_address_country of USA.
If you wanted a full list of your USA accounts, you’d use the get_full_list method.
$accounts = BeanFactory::getBean('Accounts')
->get_full_list('accounts.name','accounts.billing_address_country="USA"');
foreach($accounts as $item)
{
var_dump($item->name);
}
The syntax of get_full_list is a little weird. Let’s take a look at its method prototype
#File: data/SugarBean.php
function get_full_list($order_by = "", $where = "", $check_dates=false, $show_deleted = 0)
The first parameter ($order_by) is the ORDER BY clause for the eventual SQL statement that will generated.
The second parameter ($where) is the literal SQL WHERE clause for the query. Again, we have no parameterized queries here, so we’ll need to manually quote any user input. The bean object has a reference to your database handler, which will give you access to the quote method, (notice the $o->db->quote( call below)
$o = BeanFactory::getBean('Accounts');
$accounts = $o
->get_full_list('accounts.name','accounts.billing_address_country="'.$o->db->quote($_POST['country']).'"');
Also, due to a quirk of the querying system, you’ll need to know and include the table name in these where clauses.
The third parameter ($check_dates) is a boolean that will control the format of any date fields populated by the object. If false/omitted, the dates will be returned in the native database format
2013-02-22 05:46:05
If set to true, SugarCRM will format those dates based on its configuration, as well as convert the date to the local timezone. By default (and in the united states) this means something like this.
02/21/2013 09:46pm
Finally, the fourth parameter ($show_deleted) controls whether deleted records are returned or not. Remember, SugarCRM never deletes data, it only marks it in the database as deleted. By setting this parameter to true, your query will include items that have been deleted.
While not the tightest abstraction in the world, the get_full_list method is sufficiently powerful to let you get at any data your project might need.
Paginating Collections
Like all ActiveRecord-ish querying methods, returning a massive number of objects can quickly consume system resources, especially with large datasets. To help counter this (as well as help out some UI features we’ll discuss in later articles), SugarCRM bean models provide the get_list method. Where get_full_list returns an array of every object of a particular bean-type in the system, get_list will return a pagination result.
At first blush, get_list and get_full_list seem to provide an identical programming interface.
$o = BeanFactory::getBean('Accounts');
$accounts = BeanFactory::getBean('Accounts')
->get_list('accounts.name','accounts.billing_address_country="'.$o->db->quote('USA').'"');
The first parameter is, again, the ORDER BY clause, while the second is the WHERE clause. However, if you attempt to loop over the resulting array, you’re in for a surprise
foreach($accounts as $account)
{
var_dump($account->name);
}
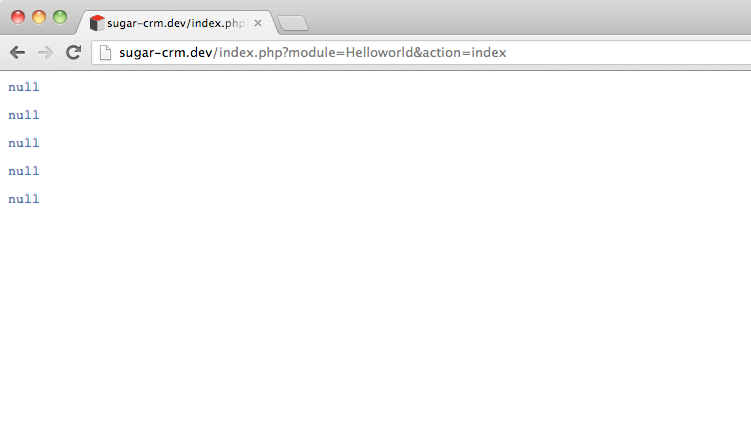
After seeing the above there’s multiple thoughts that will fly though any developer’s head. Only five rows returned? Well, maybe that’s the pagination — but why is name a null field?
While these are rational, logical thoughts, they’re completely off base. The get_list method does not return an array of objects. Instead, it returns a 5 key PHP array. Try this instead
var_dump(
array_keys($accounts)
);
You should see the five keys in your $accounts array.
array (size=5)
0 => string 'list' (length=4)
1 => string 'row_count' (length=9)
2 => string 'next_offset' (length=11)
3 => string 'previous_offset' (length=15)
4 => string 'current_offset' (length=14)
We can find the array of objects we were looking for in the list item of the array. Run the following code instead
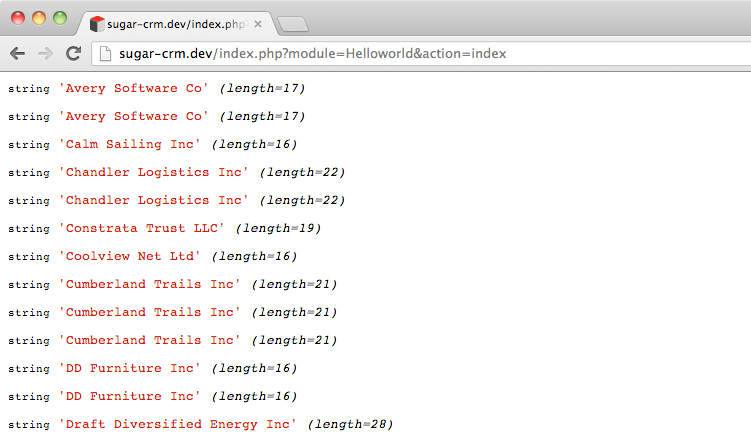
foreach($accounts['list'] as $item)
{
var_dump($item->name);
}
and you’ll see the first 20 account names output.
The inconsistent behavior between get_list and get_full_list is the sort of thing that can kill the productivity of a junior, or even intermediate level PHP programmer. Once a developer makes a logical assumption about the code — get_list must return an array of objects — they’ll spend hours spinning their wheels trying to figure out what they did wrong with their code.
This is one area where I’ll (grudgingly) admit the more static languages like C# and Java have the dynamic languages beat — you always know your return type in those languages and never have to worry about mystery arrays.
Pagination Rules
The number of items on a page in SugarCRM is controlled via the global configuration variable list_max_entries_per_page. If you open up config.php, you’ll see the following line
#File: config.php
'list_max_entries_per_page' => 20,
This tells SugarCRM that get_list should return 20 items, which in turns means the user interface grids will show only 20 rows. If we changed this to 10, SugarCRM would show 10 rows by default. You can override this default by using the fourth parameter of get_list. The following code returns a list of 7 items.
$o = BeanFactory::getBean('Accounts');
$accounts = BeanFactory::getBean('Accounts')
->get_list(
'accounts.name',
'accounts.billing_address_country="'.$o->db->quote('USA').'"',
null,
7
);
That’s our first page of records fetched, but you’re probably wondering how to fetch the second page of records. This is where the other items in the get_list array come into play.
SugarCRM’s ORM isn’t build around “pages”. Instead, it’s built around the idea of offsets. That is, you tell the get_list method how many rows it should skip before returning anything. By default, your offset is zero, so get_list returns the first 20 rows. If you wanted to get the 5th – 25th row, your offset would be 4 (i.e. skip the first four rows)
Your offset is the third parameter to the get_list method. The above scenario looks like the following in code.
$o = BeanFactory::getBean('Accounts');
$accounts = $o->get_list(
'accounts.name',
'accounts.billing_address_country="'.$o->db->quote('USA').'"',
4
);
If we return to the get_list array, we’ll remember it had a few keys related to offsets
array (size=5)
0 => string 'list' (length=4)
1 => string 'row_count' (length=9)
2 => string 'next_offset' (length=11)
3 => string 'previous_offset' (length=15)
4 => string 'current_offset' (length=14)
The field we’re interested in is next_offset. This field contains the correct offset for us to fetch the next logical page of items. So, if we wanted the first two pages of rows, we’d do something like this
$o = BeanFactory::getBean('Accounts');
$page_one = $o->get_list(
'accounts.name',
'accounts.billing_address_country="'.$o->db->quote('USA').'"'
);
$page_two = $o->get_list(
'accounts.name',
'accounts.billing_address_country="'.$o->db->quote('USA').'"',
$page_one['next_offset']
);
Here we’ve called get_list twice. For the the first call we omitted the offset parameter, which means SugarCRM will fetch the first 20 rows. Then, we use the value returned in next_offset to fetch the next 20 rows.
This method of pagination is a little more unwieldily that simply saying “give me page N”, but it does provide you with more fine grained control over what does and doesn’t get returned. As we always say: It’s better to work in a system’s abstractions then trying to bring your own into a system not built for them.
Wrap Up
Today we covered the basics of SugarCRM’s bean models. There’s still plenty of things to cover — relationships to other models, Sugar’s built in UI code, etc. We’ll get to those items eventually, but next time we’re going to look at what it takes to create your own SugarCRM bean model.